
Before we dive into the details, I'd like to say that you may don't need a Sidekiq liveness probe if you only get a few Sidekiq instances on production and it's integrated with an error tracking system. Better to keep things simple.
The Issue
The only issue I've encountered on Production about Sidekiq workers not working is the outage of Redis. Sidekiq noticed this but didn't restart, just pending there. It's a good design since lots of companies these days still not using docker.
From the Source Code of Sidekiq, we can see that it catches all the errors, so the Sidekiq process will keep running in the background.
rescue => e
# ignore all redis/network issues
logger.error("heartbeat: #{e}")
# don't lose the counts if there was a network issue
Processor::PROCESSED.incr(procd)
Processor::FAILURE.incr(fails)
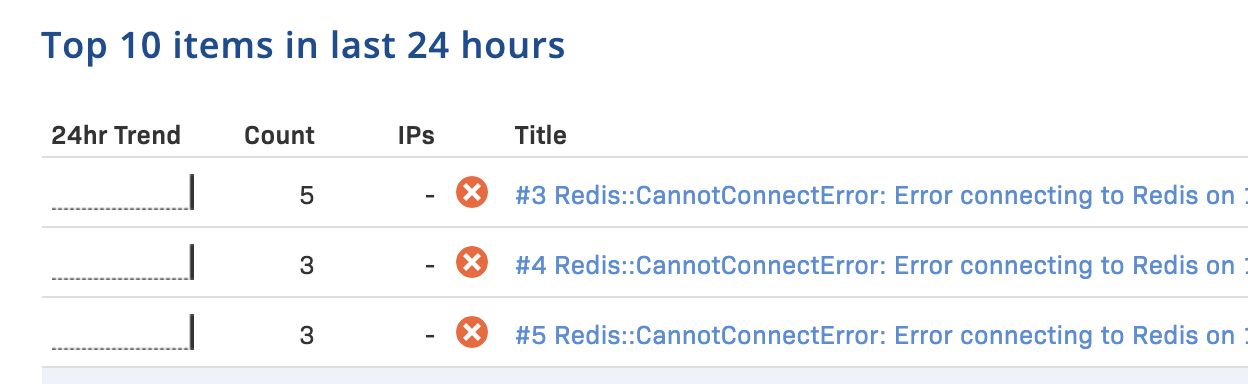
endHere are the Sidekiq error messages when Redis server is down.
2020-12-20T10:47:09.966Z pid=12434 tid=6ka ERROR: heartbeat: Error connecting to Redis on 127.0.0.1:6379 (Errno::ECONNREFUSED)
2020-12-20T10:47:44.693Z pid=12434 tid=6jy WARN: Redis::CannotConnectError: Error connecting to Redis on 127.0.0.1:6379 (Errno::ECONNREFUSED)Solution
The solution is simple, you can just integrate an error tracking service into your project, for example, Rollbar, to log all the errors on production and create an alert message to your Slack channel.
I've tested it on my local, it runs out that Rollbar works well on this kind of thing.
But we can take a further step forward, I'd like to make sure no job will be lost after restart Sidekiq.
How to restart Sidekiq without loosing Jobs
When the job is processing in the background, you should not just kill the Sidekiq process directly, instead we want to restart it gracefully.
System provides Job Signals to interact with background jobs, we call it Job Control, and we can tell the job to stop ingesting new jobs by sending signals.
Sidekiq responds to Several Signals, the signal that can be used here is SIGTSTP.
The SIGTSTP signal is an interactive stop signal. Unlike SIGSTOP, this signal can be handled and ignored.
Your program should handle this signal if you have a special need to leave files or system tables in a secure state when a process is stopped. For example, programs that turn off echoing should handle SIGTSTP so they can turn echoing back on before stopping.
Finally, we get the right signal for stopping the background job, but when we send this signal to Sidekiq. Since I'm using Kubernetes as our pods' management, the following tutorial is about the implementation in K8s.
How to implement Sidekiq Probes In Kubernetes
The first thing about when to send the signal is that we must figure out the Lifecycle of Kubernetes pods termination. It looks like this:
- The pod is set to the
TerminatingState and stop getting new traffic preStop Hookis executedSIGTERMsignal is sent to the pod- Kubernetes waits for a grace period
SIGKILLsignal is sent to the pod, and the pod is removed
To set a gracefully restart, we can send the signal SIGTSTP at #2 stage proStop Hook with a terminationGracePeriodSeconds value to let the processing jobs finally to be done.
There is already a Gem to support Sidekiq Liveness Probe and readinessProbe .
spec:
containers:
- name: my_app
image: my_app:latest
env:
- name: RAILS_ENV
value: production
command:
- bundle
- exec
- sidekiq
ports:
- containerPort: 7433
livenessProbe:
httpGet:
path: /
port: 7433
initialDelaySeconds: 80 # app specific. Time your sidekiq takes to start processing.
timeoutSeconds: 5 # can be much less
readinessProbe:
httpGet:
path: /
port: 7433
initialDelaySeconds: 80 # app specific
timeoutSeconds: 5 # can be much less
lifecycle:
preStop:
exec:
# SIGTERM triggers a quick exit; gracefully terminate instead
command: ["kube/sidekiq_quiet"]
terminationGracePeriodSeconds: 60 # put your longest Job time here plus security time.Please aware that you'd better not run time-consuming jobs, or you may see your Sidekiq pods in Terminating status in a long time.
